Cenário anterior: Verificação de logs nos servidores feita de forma manual. Conectar via MSTSC e verificar logs no EventView.
Solução: Por ter conhecimento na solução Eventlog Analyzer da Manage Engine e por ser uma ferramenta totalmente gratuita e mundialmente conhecida.
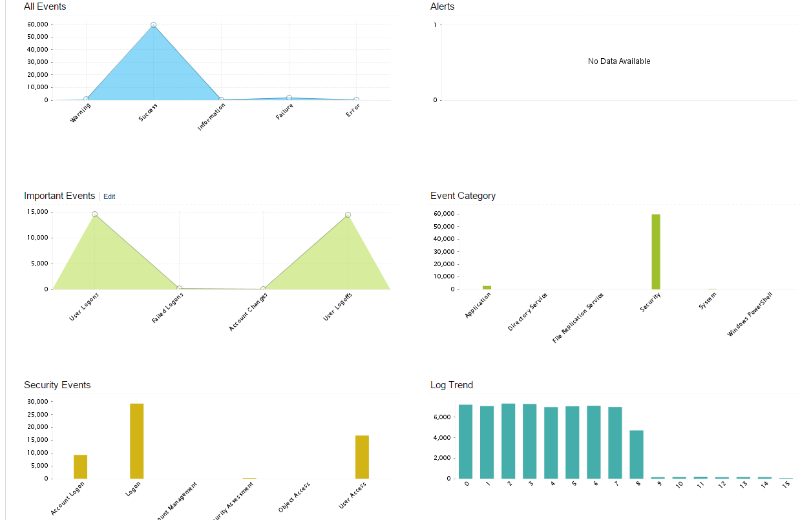
Realizamos o estudo do ambiente e identificamos os servidores chaves. Habilitamos os protocolos de SNMP/WMI e começamos a coletar os logs, agora é possível verificar os logs de todos os servidores em um ponto centralizado. Facilitando bastante e identificação de error/warnings. Temos a possibilidade de tirar relatórios como por exemplo:
• Windows Logon, Failed e logoff
• GPO Changes
• OU Changes
• User Account Management
• Policy Changes
• Domains Events
• E muito mais
Conseguimos gerar relatório de compliance, FISMA, SOX, GLBA, PCI, HIPAA e ISSO 27001:2013. Com um simples clique visualizamos cada item. Agendar relatórios que serão enviados automaticamente para o e-mail cadastrado. Como também alertas em tempo real de algum log em especifico que julgarmos necessário.
É possível localizar facilmente um log especifico através de palavras chaves e inclusive com strings.
Projeto – OpManager Monitoramento da Infra-estrutura
Cenário anterior: Verificação de disponibilidade nos servidores feita de forma manual. Conectar via MSTSC, validando sua disponibilidade.
Solução: Por ser certificado na solução OpManager da Manage Engine, por ser uma ferramenta totalmente gratuita e mundialmente conhecida.
Realizamos o estudo do ambiente e identificamos os servidores chaves.
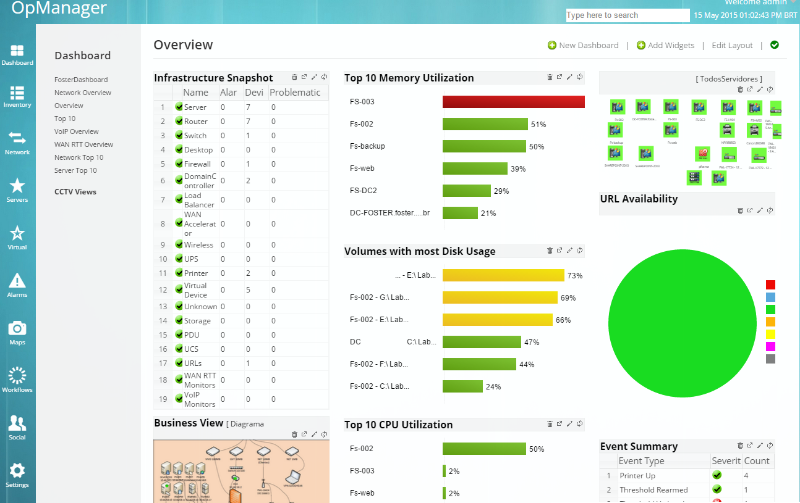
Habilitamos os protocolos de SNMP/WMI e começamos a monitorar, não só a disponibilidade dos servidores, temos agora o monitoramento de CPU, DISCO, MEMORIA, etc. Estamos monitorando o processo do antivírus, alguns do serviços do Windows e não Windows, URL (Intranet), quantidade de processos ativos e alguns arquivos/pastas que julgamos necessário.
Assim que ocorre alguma indisponibilidade fomos alertados por e-mail. Colocamos uma Dashboard onde temos uma visão macro do ambiente e identificamos facilmente qualquer problema. Temos três tipos de alertas critico (cor vermelha), problema (cor laranja) e atenção (cor amarelo).
Criamos diagramas, tiramos foto dos Hacks e importamos para o OpManager facilitando a identificação do problema e a resolução do mesmo.
Relatórios agendados sendo enviados semanalmente para grupo de e-mail.
Link do projeto linkedind: https://www.linkedin.com/pulse/projetos-monitoramento-e-logs-tiago-toledo-faria/?trk=prof-post